mysql语句中去除重复的记录条数小结
今天在上网查阅sql语句的相关资料的时候,在自学IT网上面看到一道sql基础语句的面试题目,于是自己就在电脑上面测试了下,结果看似满基础的东西,却还是卡克了,最后在于同事的讨论中终于还是搞定了这个小问题,在下午不是很忙的时候,便抽出一点时间来整理下这道题目,做个相关的总结,面得以后自己又搞忘记了.也方便以后相关的查阅.
以下是相关题目的截图说明和题目要求: 删除掉表中的重复记录的条数,保证相同的记录只有一条即可. (以下为了方便测试,将相关的建表语句和sql查询语句都列出来.)
CREATE TABLE `chongfu` (
`id` mediumint(8) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
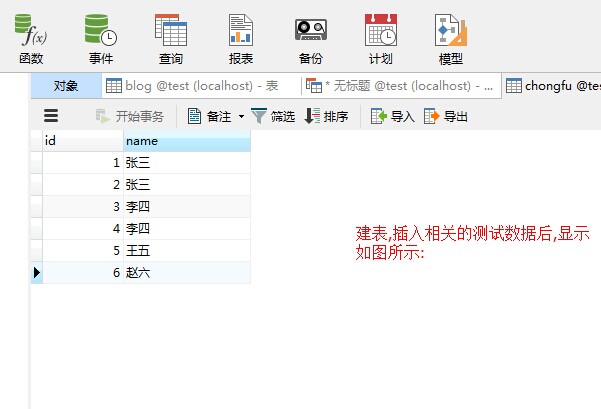
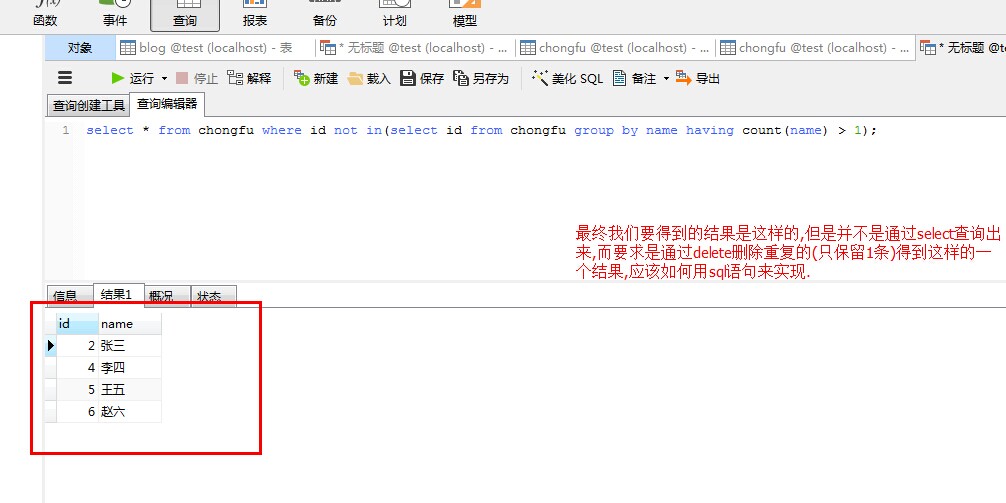
插入相关的数据后如上图所示; 最终需要达到的相关查询要求是如下截图(但要求不要用select语句,而是要用delete语句来实现);
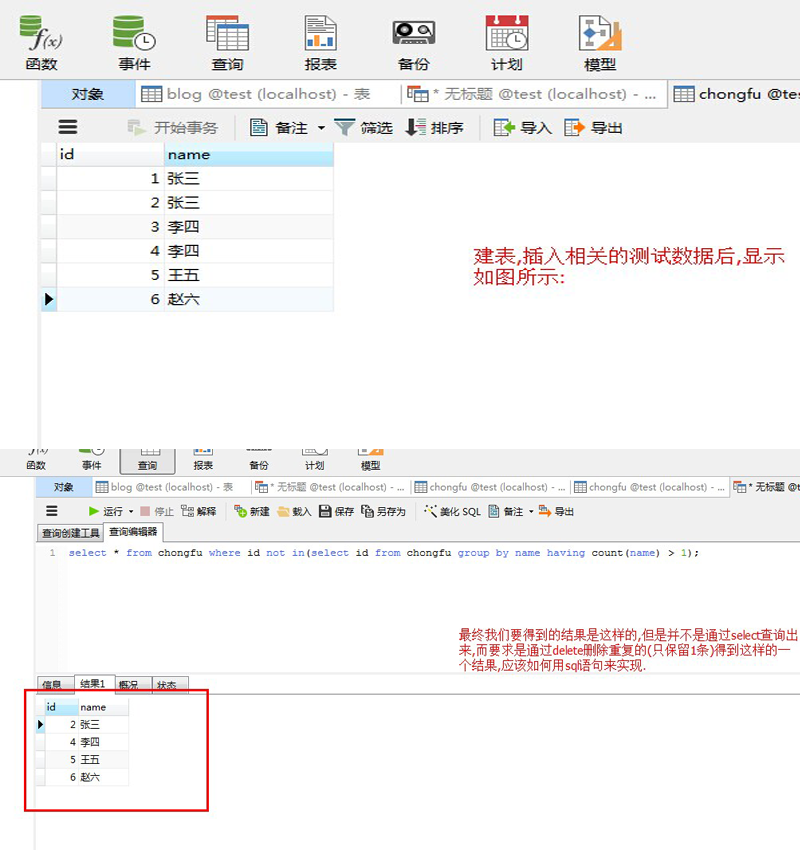
最终整理的对比相关的综合图片如下:
开始在自己的电脑上面测试的时候,思路没有错误,就是没有给表取别名在navicat中运行相关的sql语句是一直报错.最后经过相关的测试,得到最终的答案的sql语句为:
delete from chongfu where id in (select a.id from (select id from chongfu group by name having count(name) > 1) as a );
//注意要给表区别名,否则在mysql中会报错.其他数据库中应该不需要的.
//单独查询select id from chongfu group by name having count(name) > 1;可以得到id=1和id=3的两列
而如果要是用select语句的话,下面这句就可以搞定:
select * from chongfu where id not in(select id from chongfu group by name having count(name) > 1);